高性能GPU服务器AI网络架构(上篇)
在大规模模型训练的领域中,构建高性能GPU服务器的基础架构通常依托于由单个服务器搭载8块GPU单元所组成的集群系统。这些服务器内部配置了如A100、A800、H100或H800等高性能GPU型号,并且随着技术发展,未来可能还会整合{4, 8} L40S等新型号GPU。下图展示了一个典型的配备了8块A100 GPU的服务器内部GPU计算硬件连接拓扑结构示意图。
本文将依据上述图表,对GPU计算涉及的核心概念与相关术语进行深入剖析和解读。
下载链接:
人形机器人专题2:编码器
人形机器人专题3:IMU传感器专题
人形机器人专题4:减速专题研究
PCIe交换机芯片
在高性能GPU计算的领域内,关键组件如CPU、内存模块、NVMe存储设备、GPU以及网络适配器等通过PCIe(外设部件互连标准)总线或专门设计的PCIe交换机芯片实现高效顺畅的连接。历经五代技术革新,目前最新的Gen5版本确保了设备间极为高效的互连性能。这一持续演进充分彰显了PCIe在构建高性能计算系统中的核心地位,显著提升了数据传输速度,并有力地促进了现代计算集群中各互联设备间的无缝协同工作。
NVLink概述
NVLink定义
NVLink是英伟达(NVIDIA)开发并推出的一种总线及其通信协议。NVLink采用点对点结构、串列传输,用于中央处理器(CPU)与图形处理器(GPU)之间的连接,也可用于多个图形处理器之间的相互连接。与PCI Express不同,一个设备可以包含多个NVLink,并且设备之间采用网格网络而非中心集线器方式进行通信。该协议于2014年3月首次发布,采用专有的高速信号互连技术(NVHS)。
该技术支持同一节点上GPU之间的全互联,并经过多代演进,提高了高性能计算应用中的双向带宽性能。
NVLink的发展历程:从NVLink 1.0到NVLink 4.0
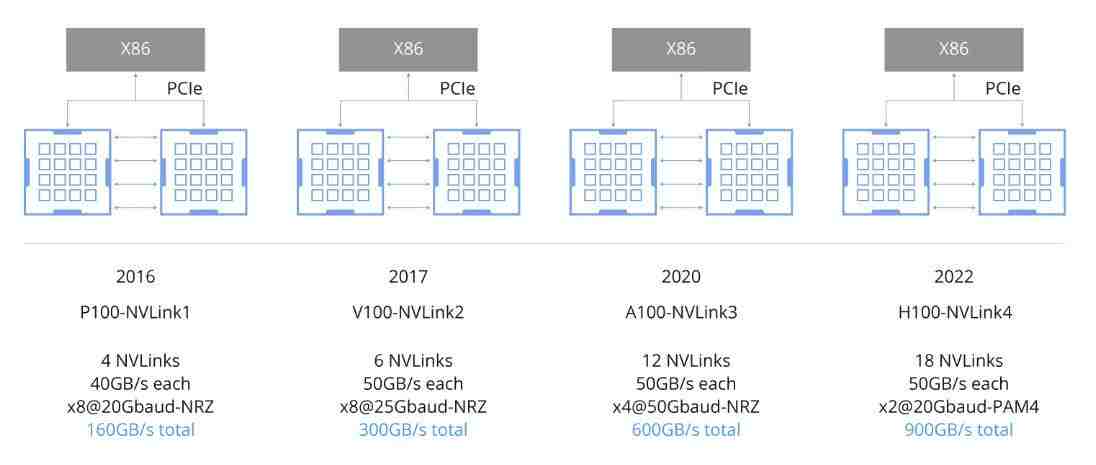
NVLink技术在高性能GPU服务器中的演进如下图所示:
NVLink 1.0
连接方式:采用4通道连接。 总带宽:实现高达160 GB/s的双向总带宽。 - 用途:主要用于加速GPU之间的数据传输,提升协同计算性能。
NVLink 2.0
- 连接方式:基于6通道连接。
总带宽:将双向总带宽提升至300 GB/s。 - 性能提升:提供更高的数据传输速率,改善GPU间通信效率。
NVLink 3.0
连接方式:采用12通道连接。 - 总带宽:达到双向总带宽600 GB/s。
新增特性:引入新技术和协议,提高通信带宽和效率。
NVLink 4.0
连接方式:使用18通道连接。 - 总带宽:进一步增加至双向总带宽900 GB/s。
性能改进:通过增加通道数量,NVLink 4.0能更好地满足高性能计算和人工智能应用对更大带宽的需求。
NVLink 1.0、2.0、3.0和4.0之间的关键区别主要在于连接通道数目的增加、所支持的总带宽以及由此带来的性能改进。随着版本迭代,NVLink不断优化GPU间的数据传输能力,以适应日益复杂且要求严苛的应用场景。
NVSwitch
NVSwitch是NVIDIA专为满足高性能计算和人工智能应用需求而研发的一款交换芯片,其核心作用在于实现同一主机内部多颗GPU之间的高速、低延迟通信。
下图呈现了一台典型配置8块A100 GPU的主机硬件连接拓扑结构。
下图展示的是浪潮NF5488A5 NVIDIA HGX A100 8 GPU组装侧视图。在该图中,我们可以清楚地看到,在右侧六个大型散热器下方隐蔽着一块NVSwitch芯片,它紧密围绕并服务于周围的八片A100 GPU,以确保GPU间的高效数据传输。
NVLink交换机
NVLink交换机是一种由NVIDIA专为在分布式计算环境中的不同主机间实现GPU设备间高性能通信而设计制造的独立交换设备。不同于集成于单个主机内部GPU模块上的NVSwitch,NVLink交换机旨在解决跨主机连接问题。可能有人会混淆NVLink交换机和NVSwitch的概念,但实际上早期提及的“NVLink交换机”是指安装在GPU模块上的切换芯片。直至2022年,NVIDIA将此芯片技术发展为一款独立型交换机产品,并正式命名为NVLink交换机。
HBM(高带宽内存)
传统上,GPU内存与常见的DDR(双倍数据速率)内存相似,通过物理插槽插入主板并通过PCIe接口与CPU或GPU进行连接。然而,这种配置在PCIe总线中造成了带宽瓶颈,其中Gen4版本提供64GB/s的带宽,Gen5版本则将其提升至128GB/s。
为了突破这一限制,包括但不限于NVIDIA在内的多家GPU制造商采取了创新手段,即将多个DDR芯片堆叠整合,形成了所谓的高带宽内存(HBM)。例如,在探讨H100时所展现的设计,GPU直接与其搭载的HBM内存相连,无需再经过PCIe交换芯片,从而极大地提高了数据传输速度,理论上可实现显著的数量级性能提升。因此,“高带宽内存”(HBM)这一术语精准地描述了这种先进的内存架构。
HBM的发展历程:从HBM1到HBM3e
带宽单位解析
在大规模GPU计算训练领域,系统性能与数据传输速度密切相关,涉及到的关键通道包括PCIe带宽、内存带宽、NVLink带宽、HBM带宽以及网络带宽等。在衡量这些不同的数据传输速率时,需注意使用的带宽单位有所不同。
在网络通信场景下,数据速率通常以每秒比特数(bit/s)表示,且为了区分发送(TX)和接收(RX),常采用单向传输速率来衡量。而在诸如PCIe、内存、NVLink及HBM等其他硬件组件中,带宽指标则通常使用每秒字节数(Byte/s)或每秒事务数(T/s)来衡量,并且这些测量值一般代表双向总的带宽容量,涵盖了上行和下行两个方向的数据流。
因此,在比较评估不同组件之间的带宽时,准确识别并转换相应的带宽单位至关重要,这有助于我们全面理解影响大规模GPU训练性能的数据传输能力。
文章来源:
https://community.fs.com/cn/article/unveiling-the-foundations-of-gpu-computing1.html
下载链接:
服务器行业深度报告:AI和“东数西算”双轮驱动,服务器再起航
1、英伟达GTC 2024主题演讲:见证AI的变革时刻
2、展望GTC变革,共享AI盛宴
3、英伟达GTC专题:新一代GPU、具身智能和AI应用
500+份重磅ChatGPT专业报告
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
关键词
英伟达
芯片
架构
带宽
网络
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。